BPB: Understanding Bits Per Byte from First Principles
BPB (Bits per Byte) is an eval/loss metric that is used usually when evaluating the inter LLM results, I recently found it in Karpathy’s Autoresearch project where its used by the Agent system to compare different models.
You may have seen this metric before, but generally when evaluating LLMs, we mostly use Cross-Entropy Loss, Perplexity, etc.
BPB sounds like a fancy name, and I wanted to dig deeper into the metric to see exactly what it measures. To do that, I went through Information Theory to understand it from first principles.
Let’s start with what BPB actually measures, and by the end, we’ll see why Cross-Entropy (CE) — while a great metric for evaluating the same model over time — can be highly misleading when comparing different models.
What is Information?
The way Information Theory defines it is very intriguing: Information is the resolution of surprise.
What this essentially means is that if you are having a conversation with a friend and you can predict what they are about to say with 100% accuracy, you are not surprised at all by their words. Hence, they conveyed 0 information to you.
The more surprised you are by the output, the more information is transferred. Information isn’t just physical data traveling through a wire or optical fiber.
Because it depends on your current state of knowledge, two people can extract completely different amounts of information from the exact same output a machine spits out. Doesn’t that sound weird?
This also means that Information has a very tight bond with probability. Another way to put this is: the greater the number of Yes/No questions you have to ask a system to figure out an event, the more information that event conveys.
Mathematically, the Information of a single event is calculated as \(\boldsymbol{-\log_2(p)}\) (where $p$ denotes the probability of the event, e.g., 0.5 for a coin toss).
The average expected information across all possible events in a system is defined by Shannon Entropy:
\[\boldsymbol{H = - \sum p \times \log_2(p)}\]The unit of this value is bits (representing those Yes/No questions).
What is Compression?
Once you understand what Information is in real terms, it’s time to understand what compression is at its core.
Take a book, for example. If we want to compress it, the absolute smallest you could ever compress that book without losing any plot points is its Shannon Entropy.
- High Shannon Entropy just means the book is complex and rich in story.
- It represents the true information of reality.
You may ask: what will this (ideal) compression look like? Again, for simplicity, say you only have 4 letters in the book—A, B, C, and D—and these 4 letters form the entire text.
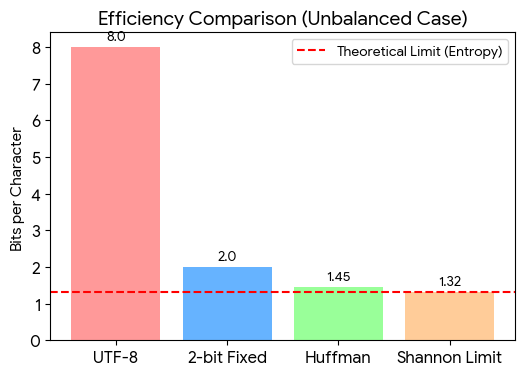
If you’re using standard UTF-8 format, each character takes at least 1 byte (and at most 4 bytes). You need at least 4 bytes to represent all 4 of them in memory. Now, assume each character has an equal probability of appearing across the book. We can calculate the Shannon Entropy of each character, which comes out to exactly 2 bits. We could use Huffman Coding to achieve this compression.
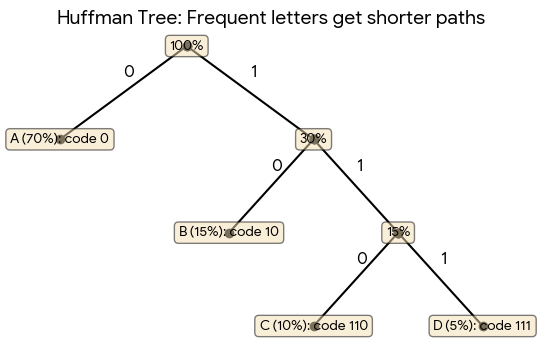
But assume the distribution is not uniform. Let’s say it is biased: A (70%), B (15%), C (10%), D (5%). If we calculate the Shannon Entropy now, it comes out to ~1.32 bits/char. If we draw out a Huffman tree for this, the actual compression will be 1.45 bits/char.
How do Shannon Entropy bits relate to actual memory bits?
Once you understand the concept of information (theoretical bits) and the compression of real data into storage (hardware bits), we need to understand how they relate to each other.
These are two entirely different things: one represents the surprise a system experiences, and the other represents storing real-world data.
If I flip a coin and the result is hidden, I will experience exactly 1 bit of surprise. If I want to represent that result in computer memory, I’ll need 1 physical bit of storage (a 0 or a 1).
Shannon’s Source Coding Theorem mathematically proves that you can never use fewer physical bits than you have theoretical bits.
Now it’s time for BPB
Once this intuition is formed—understanding what Information is and how we compress it—Bits per Byte is not that difficult to grasp.
BPB is a metric to understand data compression, which essentially tells us how efficiently a model can transfer information using fewer bits.
When evaluating an LLM, we first calculate the Cross-Entropy (CE). This tells us the loss per token: how surprised the model is during its next-token prediction, or how uninformed the model is when predicting that token. In simple terms: the higher the CE, the less confident the model is.
The unit of Cross-Entropy is generally “nats” (based on the natural logarithm). Before calculating BPB, this is converted to bits (using a base-2 logarithm).
These “bits” need to be understood correctly.
Let’s assume two people, Person A and Person B, both have the exact same LLM (say, Llama 3B) and want to exchange some information. The text they want to send is “The sky is Blue”.
Take the token “The”. Assume the model naturally assigns a 10% probability to this token being the start of a sentence. Person A needs to send at least $\boldsymbol{-\log_2(0.1) \approx 3.32}$ bits of mathematical hints to guide Person B’s machine to the word “The”.
Now, say the context “The sky is” has already been communicated. The next token is “Blue”, which the model perfectly predicts with a 95% probability. The hint Person A needs to convey drops massively to $\boldsymbol{-\log_2(0.95) \approx 0.07}$ bits.
This is what prediction-as-compression is: the model is able to compress the word “Blue” much better than “The” because it has context, meaning it has understood the internal patterns of the text.
Finally, we divide this CE value by the raw bytes of the token to get the absolute byte-level compression. This is known as Bits per Byte (BPB).
Why do we divide entropy by bytes?
Assuming this makes sense so far, the natural next question is: Why do we even want to divide entropy by bytes?
Take two models, for instance: Model 1 has a 16k vocabulary size, and Model 2 has an 8k vocabulary size. Assume their tokenizers work on the exact same language. It is logical that Model 1’s average token length (actual characters/bytes per token) will be greater than Model 2’s, because Model 1 has a larger dictionary and can store larger whole words.
Now, assume the word “multidimensional” is processed. It is a single token for Model 1. But for Model 2, it has to be split into two tokens: “multi” and “dimensional”.
Let’s make one more assumption: Model 1 assigns the exact same probability to “multidimensional” as Model 2 assigns to just the chunk “multi”.
If you check the CE at the token level, it will indicate similar information compression for both models on that single step. But we know that “multi” and “multidimensional” inherently carry different amounts of real-world information. One represents 5 bytes of reality, and the other represents 16 bytes.
Because Model 1 processed 16 bytes with the same confidence Model 2 needed just to process 5 bytes, token-level CE is a terrible metric for comparing differently tokenized models.
This is why we bring the CE down to the byte level—so the arbitrary token is removed from the calculation entirely. BPB is the true way to compare these models. You take the CE loss and divide it by the raw physical bytes that were just predicted. By dividing the first model’s CE by 16 and the second’s by 5, we get the true sense of surprise.
Only then can we evaluate different LLMs on the exact same benchmark.
References
I would recommend going through this series to explore more on: Information Theory
Explore why UTF-8 encoding is dominant : utf8everywhere
Tokenization fundamentals - Tokenization